Businesses need insights to make the right decisions and insights require data to become accurate. Without ETL all this is simply not possible.
That’s where ETL software comes in. ETL software lets businesses combine data from multiple disparate sources in a single data warehouse so that they can run a combination of queries and get the exact data they need to create interactive visualizations for their businesses.
The problem is that integrating disparate data sources is a cumbersome task. Unless you have connectors of each disparate source available, you will need to manually take all the data, convert it, and then load it in the data warehouse. This takes a lot of time, effort, and resources. Imagine doing this regularly, and you won’t have time to extract any impactful insights for your business.
Modern ETL software makes this all possible. Equipped with a codeless environment, these software let users extract data from disparate sources by creating data maps and automating workflows. They can even schedule jobs so that the whole process goes smoothly without human intervention.
Data Integration Challenges with Disparate Data Sources
Numerous challenges need to be taken care of when integrating data from a data source/lake to a data warehouse. We have created a list of these challenges and offered possible solutions that can help ETL experts improve the overall ETL processes by using the right tools.
 Lack of Connectors
Lack of Connectors

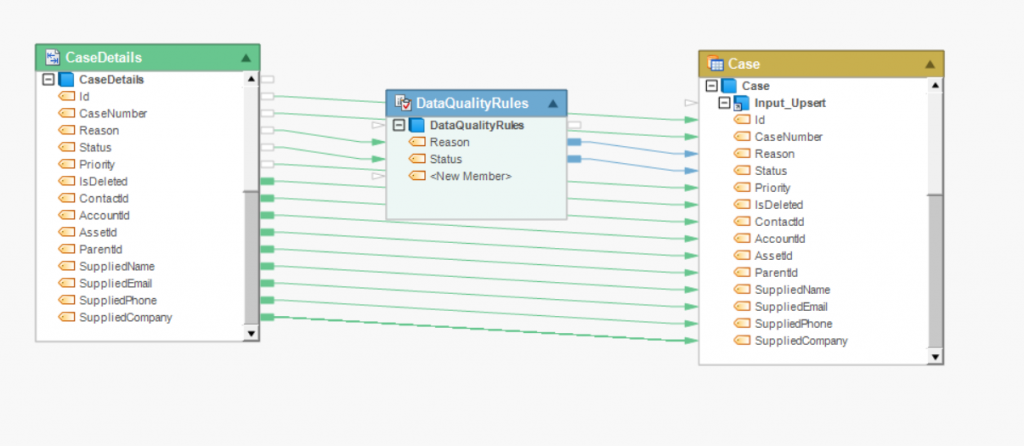
The biggest challenge companies face while ingesting data is that the connectors are not readily available. For example, copying data from Cobol to delimited files is not possible unless both Cobol and delimited files connectors are available. Even then decluttering data from Cobol is a hectic task and requires professional expertise. One wrong move and the data becomes unusable. But thanks to modern ETL software, business experts can easily open Cobol files in the staging area of the software and make changes without writing a single line of code.
Cluttered & heterogeneous data
Another challenge for companies is to declutter data to remove irrelevant fields often found in disparate data sources. I think cluttered data in this case refers to data with a lot of “noise” in it that obscures analysis at the endpoint. If this process is performed manually, it takes ages to complete. However, data integration software allows companies to complete these tasks in a matter of minutes thanks to simple GUI and the ability to add transformation and validation rules.
Poor Quality Data
Another major challenge for companies is of poor-quality data. Most information is available but places separately on the company’s servers. This type of data is not useful for getting any insights because it is simply not in any specific format. Think about the heaps of cluttered data in unstructured PDF files. What can companies do to extract and cleanse it without putting in manual work? The data is not even in a tabular format that they can copy as it is. That’s where a data extraction software comes in handy.
Problem of Duplicates
Duplicates can ruin even healthy insights and they are hard to fix especially if they exist in an unorganized data format. Let’s say you have duplicates available in a database, you can simply use a command to remove those. But what if they are available in a text file without any tables? Now you will have to manually edit the file to remove duplicates.
This is another problem that ETL software can easily solve. Simply use the duplicates removal function on the file and you will get a list of duplicates that can be easily removed.
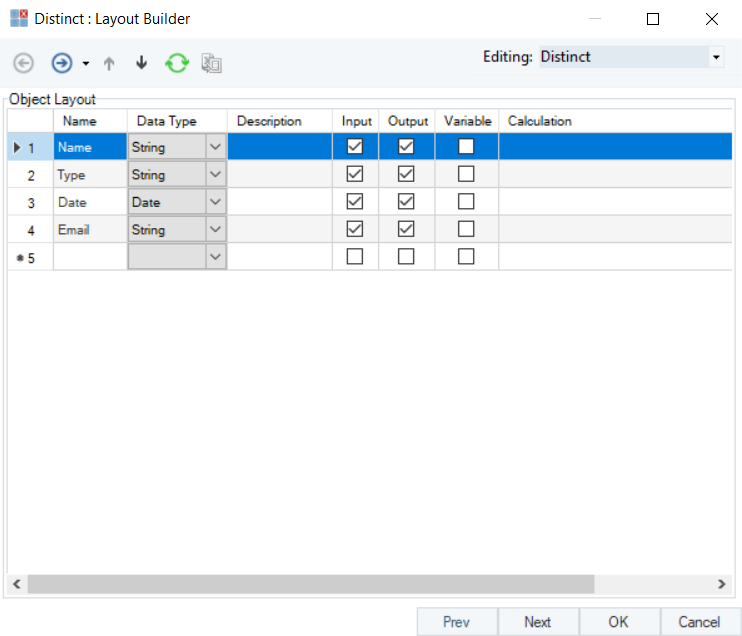
Removing duplicates from disparate data sources in Astera Centerprise. Source: Docs.Astera.com
Techniques to Integrate Disparate Data Sources
Here is a list of data integration techniques that are mostly used by businesses to integrate data from separate data sources. See the complete list of available methods below.
Manual data integration
Manual data integration is the process of manually collecting all data from a data source and then copying it to a data warehouse. The data is prepared, cleansed, reorganized, and decluttered, all using manual efforts.
Manual data integration is also possible through custom code. Companies that require data from only a few sources regularly hire ETL experts to create manual data integration processes since they are cost-effective and don’t require a paid middleware. The problem with this data integration approach is that it doesn’t work when the data sources increase. In such cases, ETL teams have to manually create a custom process for each new data source, decreasing efficiency and increasing the overall cost.
Application-based integration
Today most ETL platforms such as Astera Centerprise, Talend, Informatica, and many others allow data integration through drag and drop features with no coding requirement. Users of this software only have to connect both data sources and they can then extract data to the staging area. They can then extract data, edit it, and load it on the destination data warehouse.
Middleware data integration
Similar to application-based data integration, middleware allows data integration from legacy systems. Companies are still using many legacy systems because changing them can cost the companies millions of dollars. Extracting data from these legacy systems is not possible without the right connectors and that’s what the middleware ETL software offer. For example, Astera allows data extraction from Netezza, Teradata, Oracle, and IBM DB2. Some of these are legacy systems and integrating them into modern data warehouses is a complex process.
Data Virtualization
Sometimes it is not plausible to physically integrate data from specific data sources. This is where data virtualization technology comes in. It helps companies easily get a virtualized layer of data to extract information. In data virtualization, an image of the sourced data is available for use as a virtualization layer. Users can edit, add, or delete information in this virtualized layer and then load the final data to a data warehouse. The changes in the virtualization layer don’t alter the data in the data sources.
How Astera Centerprise Helps Integrate Disparate Data Sources
Astera Centerprise is paving way for smooth data integration processes through its drag-and-drop GUI. Centerprise users can easily source, manipulate, organize, restructure, and load data into data warehouses from over 40+ data sources.
This refined data can then be used for business intelligence purposes. Business managers can easily extract relevant information, create insightful visualizations, and make forecasts for an upward growth trajectory.
Centerprise is one of the leading platforms for integrating disparate data sources such as Cobol, IBM DB2, Netezza, Sybase, and various others. It is constantly increasing the number of connectors available so that ETL experts can perform all types of ETL jobs easily.